Introduction¶
What are Vtubers?¶
Vtubers, short for "Virtual Youtubers," are internet personalities who use virtual avatars (usually using anime-style avatars, which can be animated in Live2D, 3D, both, or neither). Originally mostly popular in Japan, in recent years they have become more popular overseas, to the point that many westerners and "normal streamers" have adopted Vtuber personas themselves.
The Vtuber industry has explosively grown in the last 2-3 years, with entire agencies such as Hololive and Nijisanji being formed to manage and promote their Vtubers.
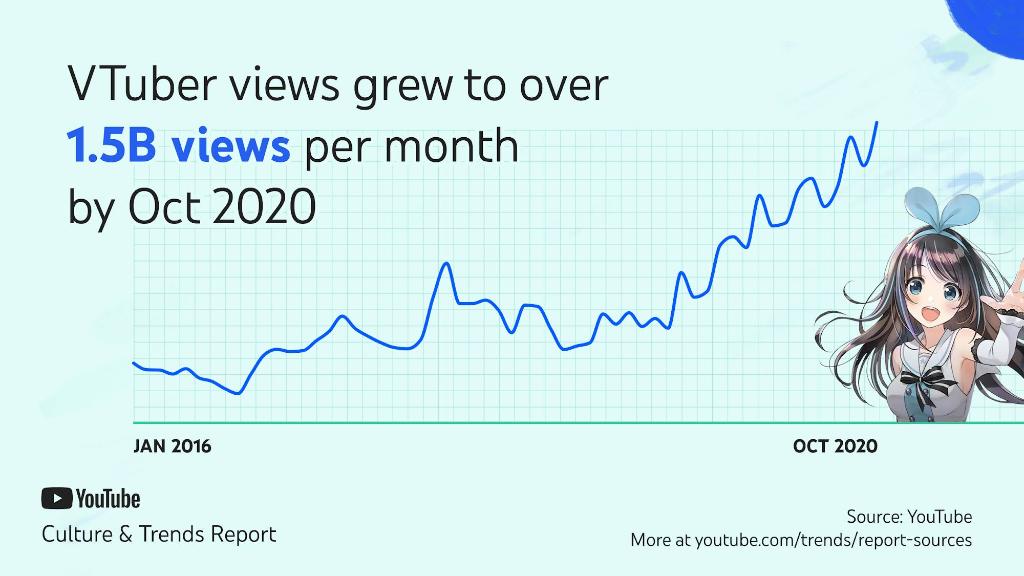
As stated on Wikipedia, YouTube's 2020 Culture and Trends report highlights VTubers as one of the notable trends of that year, with 1.5 billion views per month by October.
In summary, if you are familiar with Twitch streamers, you can think of Vtubers as similar personas but with anime avatars instead of showing their physical selves on camera.

These Vtubers primarily make money through memberships where viewers can pay to get certain perks, and through superchats where users can pay money to highlight their message. (Joining a membership can also have a message associated with it, so they are classified as superchats as well). This is big business - at my time of writing (5/1/2021), 15 of the top 20 most superchatted channels worldwide were those of Vtubers (https://playboard.co/en/youtube-ranking/most-superchatted-all-channels-in-worldwide-total). Furthermore, the top Vtubers make upwards of \$1,000,000 USD in superchat revenue in 2020, and the top 193 channels all made over \$100,000 USD (again, many of whom were Vtubers). (Of course, not all of this money goes directly to the Vtuber - YouTube themselves, and the agency the Vtuber works for [if any], both take a cut).
In this project, I aim to analyze the superchat earnings of various Vtubers, and hope to see if I can find any trends or indicators that might correlate with higher superchat earnings.
Why care?¶
As stated earlier, Vtubers are a growing business (from 2000 active Vtubers in May 2018 to over 10,000 in January 2020), and there are many people who hope to become Vtubers. The industry is so profitable that agencies have been formed to manage them. Both current and aspiring Vtubers thus stand to gain from knowing how to maximize their superchat earnings, or predict how much they might make based on how they plan to stream. This analysis aims to provide insight into both of those aspects. For fans, I feel that knowing this data is interesting in and of itself, and others have done studies regarding vtubers for fun. For example, one reddit user conducted a study of the languages used in various vtubers' chats. I hope to also post this study to reddit and get gilded.
This study could also probably be extended to non-vtuber streamers, to potentially increase the audience for who finds this data useful.
For non-vtuber fans (and vtuber fans too!), you might learn about the data science pipeline, ranging from data collection to exploratory data analysis to some regression with machine learning.



























